hadoop系列(三) 有更新!
- 37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
- 三、mapreduce示例
- (一)统计场景说明
- (二)Mapper编写
- (三)Reducer编写
- (四)Runner编写
- (五)打包工程jar
- (六)上传分析数据
- (七)上传jar包执行任务
- (八)查看任务统计结果
- 1. 查看任务执行情况
- 2. 浏览hdfs文件系统
- 3. hdfs中具体结果
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
三、mapreduce示例
(一)统计场景说明
http://blog.csdn.net/xiantian7/article/details/53169895
以单词个数统计为例,计算每个单词出现的次数。
示例:
|
hello xiaoben boom boom hello asdf dfdfd hello boom dfd boom cbaoping cmulin cyanbing cmulin cbaoping |
单词中间以“\t”tab空白键分隔。
(二)Mapper编写
|
package com.benmo.wordcount; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WcMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String[] lines = value.toString().split("\t"); for (String word : lines) { context.write(new Text(word), new LongWritable(1)); } } } |
(三)Reducer编写
|
package com.benmo.wordcount; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text word, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable num : values) { count += num.get(); } context.write(new Text(word), new LongWritable(count)); } } |
(四)Runner编写
注意:FileInputFormat使用的是mapreduce.lib.input.*下的。
|
package com.benmo.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WcRunner { public static void main(String[] args) { try { Job job; job = Job.getInstance(new Configuration()); //组建Job类,提交给mapreduce job.setJarByClass(WcRunner.class); job.setMapperClass(WcMapper.class); job.setReducerClass(WcReducer.class); //设置输入输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //构建输入输出的文件 FileInputFormat.setInputPaths(job,new Path("hdfs://master:9000/boom/data/data.txt")); FileOutputFormat.setOutputPath(job,new Path("hdfs://master:9000/boom/result/output")); //提交job到mapreduce处理 job.waitForCompletion(true); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } } |
(五)打包工程jar
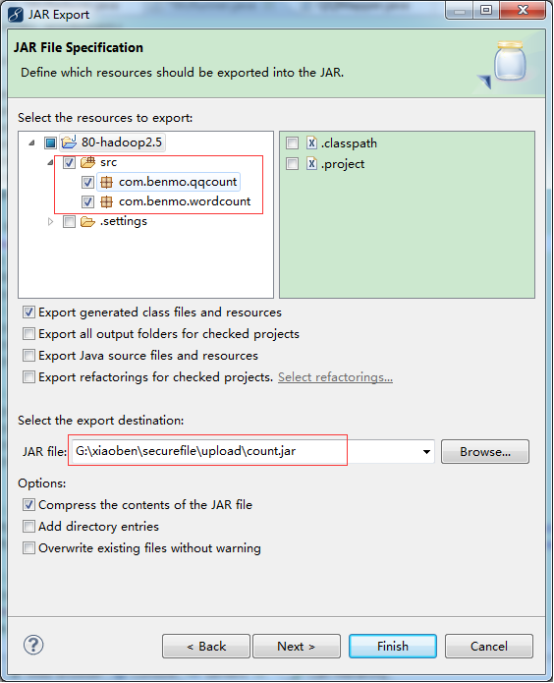
(六)上传分析数据
hdfs dfs -put data.txt /boom/data
拷贝本地文件到hdfs目录下
|
[root@master boom]# ll 总用量 21672 -rw-r--r--. 1 root root 22187454 3月 16 11:18 7b0c25ca-652f-4b69-887d-704900f49dfe -rw-r--r--. 1 root root 110 3月 28 16:22 data.txt [root@master boom]# hdfs dfs -put data.txt /boom/data |
(七)上传jar包执行任务
hadoop jar count.jar com.*.WcRunner
通过上传jar包,指定运行类来运行mapreduce任务。
|
[root@master boom]# hadoop jar count.jar com.benmo.wordcount.WcRunner 17/03/28 16:29:56 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.211.128:8032 17/03/28 16:29:57 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 17/03/28 16:29:57 INFO input.FileInputFormat: Total input paths to process : 1 17/03/28 16:29:57 INFO mapreduce.JobSubmitter: number of splits:1 17/03/28 16:29:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1490706705495_0001 17/03/28 16:29:58 INFO impl.YarnClientImpl: Submitted application application_1490706705495_0001 17/03/28 16:29:58 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1490706705495_0001/ 17/03/28 16:29:58 INFO mapreduce.Job: Running job: job_1490706705495_0001 17/03/28 16:30:08 INFO mapreduce.Job: Job job_1490706705495_0001 running in uber mode : false 17/03/28 16:30:08 INFO mapreduce.Job: map 0% reduce 0% 17/03/28 16:30:18 INFO mapreduce.Job: map 100% reduce 0% 17/03/28 16:30:27 INFO mapreduce.Job: map 100% reduce 100% 17/03/28 16:30:28 INFO mapreduce.Job: Job job_1490706705495_0001 completed successfully 17/03/28 16:30:28 INFO mapreduce.Job: Counters: 49 |
(八)查看任务统计结果
1. 查看任务执行情况
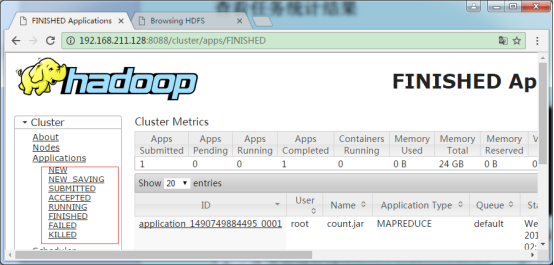
2. 浏览hdfs文件系统
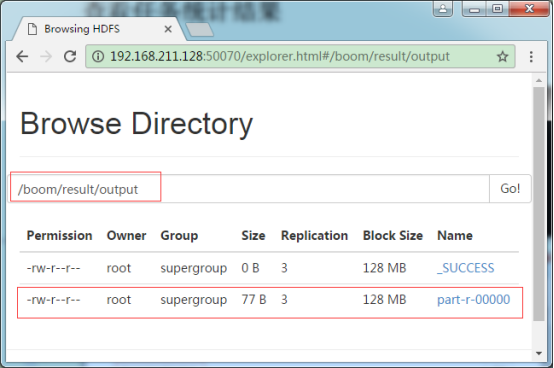
3. hdfs中具体结果
|
[root@master boom]# hdfs dfs -cat /boom/result/output/part-r-00000 asdf 1 boom 4 cbaoping 2 cmulin 2 cyanbing 1 dfd 1 dfdfd 1 hello 3 xiaoben 1 [root@master boom]# |
评论
发表评论
|
|
|