hive系列(一)安装与部署 有更新!
- 37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
- Hive安装部署
- 一、安装
- 1. 下载安装包:
- 2. 解压到指定目录
- 3. 修改运行环境配置文件
- 二、存储配置
- 1. 本地derby
- 2. 本地mysql
- 3. 远端mysql
- 1) 服务端客户端放一起配置
- 2) 服务端客服端分开配置
- 3) 运行
- 4. 存储流程原理
- 5. 内置服务
- 6. 启动方式
- 7. Hiveserver2配置
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
Hive安装部署
一、安装
1. 下载安装包:
http://www.apache.org/dyn/closer.cgi/hive/
2. 解压到指定目录
|
[root@master softs]# ll 总用量 479000 -rw-r--r--. 1 root root 90859180 5月 2 09:10 apache-hive-1.2.2-bin.tar.gz -rw-r--r--. 1 root root 214092195 4月 28 14:34 hadoop-2.7.3.tar.gz -rw-r--r--. 1 root root 185540433 4月 28 14:08 jdk-8u131-linux-x64.tar.gz [root@master softs]# tar -zxf apache-hive-1.2.2-bin.tar.gz -C /usr/program/ [root@master softs]# cd /usr/program/ [root@master program]# ll 总用量 12 drwxr-xr-x. 8 root root 4096 5月 2 17:22 apache-hive-1.2.2-bin drwxr-xr-x. 10 root root 4096 4月 28 23:37 hadoop drwxr-xr-x. 8 root root 4096 4月 28 22:19 jdk [root@master program]# mv apache-hive-1.2.2-bin/ hive [root@master program]# ll 总用量 12 drwxr-xr-x. 10 root root 4096 4月 28 23:37 hadoop drwxr-xr-x. 8 root root 4096 5月 2 17:22 hive drwxr-xr-x. 8 root root 4096 4月 28 22:19 jdk |
3. 修改运行环境配置文件
|
[root@master conf]# cp hive-env.sh.template hive-env.sh [root@master conf]# vi hive-env.sh [root@master conf]# cat hive-env.sh | grep -v "#\|^$" export HADOOP_HOME=/usr/program/hadoop export HIVE_CONF_DIR=/usr/program/hive/conf [root@master conf]# |
二、存储配置
Hive的meta数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储。远端存储比较适合生产环境。Hive官方wiki详细介绍了这三种方式,链接为:Hive Metastore。
1. 本地derby
这种方式是最简单的存储方式,只需要在hive-site.xml做如下配置便可
|
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=metastore_db;create=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> </property> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>数据路径(相对hdfs)</description> </property> </configuration> |
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库。
启动hive连接
|
[root@master program]# ./hive/bin/hive 17/05/02 10:23:14 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist Logging initialized using configuration in jar:file:/usr/program/hive/lib/hive-common-1.2.2.jar!/hive-log4j.properties hive> show databases; OK default Time taken: 0.917 seconds, Fetched: 1 row(s) |
当前启动目录下会默认生成两个db文件
|
[root@master program]# ll 总用量 40 -rw-r--r--. 1 root root 21038 5月 2 10:23 derby.log drwxr-xr-x. 10 root root 4096 4月 28 23:37 hadoop drwxr-xr-x. 8 root root 4096 5月 2 2017 hive drwxr-xr-x. 8 root root 4096 4月 28 22:19 jdk drwxr-xr-x. 5 root root 4096 5月 2 10:23 metastore_db |
开启另外一个ssh并到同一个目录下启动hive
|
[root@master program]# ./hive/bin/hive 17/05/02 10:28:02 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist Logging initialized using configuration in jar:file:/usr/program/hive/lib/hive-common-1.2.2.jar!/hive-log4j.properties Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at |
2. 本地mysql
这种存储方式需要在本地运行一个mysql服务器,并作如下配置(下面两种使用mysql的方式,需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。
mysql数据库
创建hive元数据库,分配数据库账户权限
|
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
mysql> create user 'hive'@'localhost' identified by '123456'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'localhost' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'master' IDENTIFIED BY '123456'; Query OK, 0 rows affected (0.00 sec) |
配置hive-site.xml
|
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive_mysql/warehouse</value> <description>数据路径(相对hdfs)</description> </property>
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> </configuration> |
3. 远端mysql
1) 服务端客户端放一起配置
|
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive_mysql/warehouse</value> <description>数据路径(相对hdfs)</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property>
<property> <name>hive.metastore.uris</name> <value>thrift://master:9083</value> </property> </configuration> |
注:这里把hive的服务端和客户端都放在同一台服务器上了。服务端和客户端可以拆开,将hive-site.xml配置文件拆为如下两部分
2) 服务端客服端分开配置
服务端配置:
|
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.214:3306/hive_remote?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>test1234</value> </property> </configuration> |
客服端配置
|
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property>
<property> <name>hive.metastore.uris</name> <value>thrift://192.168.1.188:9083</value> </property> </configuration> |
3) 运行
启动服务端:
|
[root@master hive]# ./bin/hive --service metastore Starting Hive Metastore Server 17/05/02 13:52:00 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist |
在0.10 0.11或者之后的HIVE版本 hive.metastore.local 属性不再使用,删除掉该配置。
|
[root@master hive]# ./bin/hive --service metastore Starting Hive Metastore Server |
客户端连接
|
[root@master hive]# ./bin/hive
hive> show databases; OK default mysqltest Time taken: 0.817 seconds, Fetched: 2 row(s) hive> |
4. 存储流程原理
hive不是一个数据库,只是一个仓储工具。数据是存储在hdfs中,由配置文件中的hive.metastore.warehouse.dir指定。hive表结构信息存储在mysql中,mysql中的元数据是表结构与hdfs真实数据的映射关系数据。
创建一个数据库,并创建一个tb_test表,插入一条示例数据:
|
hive> show databases; OK default mysqltest hive> create database boomtest; OK Time taken: 1.094 seconds hive> show databases; OK boomtest default mysqltest Time taken: 0.22 seconds, Fetched: 3 row(s) hive> drop database mysqltest; OK Time taken: 0.352 seconds hive> show databases; OK boomtest default Time taken: 0.035 seconds, Fetched: 2 row(s) hive> use boomtest; OK Time taken: 0.041 seconds hive> create table tb_test (id int,name string); OK Time taken: 0.413 seconds hive> desc tb_test; OK id int name string Time taken: 0.195 seconds, Fetched: 2 row(s) hive> create table tb_test2 like tb_test; OK Time taken: 0.102 seconds hive> show tables; OK tb_test tb_test2 Time taken: 0.071 seconds, Fetched: 2 row(s) hive> desc tb_test2; OK id int name string Time taken: 0.114 seconds, Fetched: 2 row(s) hive> insert into tb_test values(1,'dfdfddf'); Query ID = root_20170502143319_81ce984f-7898-45a4-9198-1893493f1fd8 Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1493689953824_0001, Tracking URL = http://master:8088/proxy/application_1493689953824_0001/ Kill Command = /usr/program/hadoop/bin/hadoop job -kill job_1493689953824_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2017-05-02 14:33:36,850 Stage-1 map = 0%, reduce = 0% 2017-05-02 14:33:46,257 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.83 sec MapReduce Total cumulative CPU time: 1 seconds 830 msec Ended Job = job_1493689953824_0001 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to: hdfs://master:9000/user/hive_mysql/warehouse/boomtest.db/tb_test/.hive-staging_hive_2017-05-02_14-33-19_837_1507014969512216506-1/-ext-10000 Loading data to table boomtest.tb_test Table boomtest.tb_test stats: [numFiles=1, numRows=1, totalSize=10, rawDataSize=9] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 1.83 sec HDFS Read: 3600 HDFS Write: 82 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 830 msec OK Time taken: 29.066 seconds hive> select * from tb_test; OK 1 dfdfddf Time taken: 0.258 seconds, Fetched: 1 row(s) hive> |
在hive中可以查询到tb_test中的数据,该表数据在hdfs中相对应的数据存储路径为
/user/hive_mysql/warehouse/boomtest.db/tb_test
查看http://192.168.211.132:50070/explorer.html目录浏览结构如下:
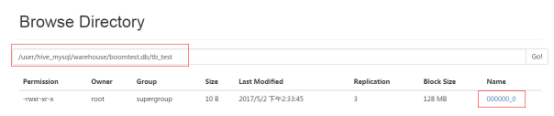
使用hdfs命令下载该文件到本地,本地查看能看到真实存储在hdfs中的数据:
|
[root@master boom]# hdfs dfs -get /user/hive_mysql/warehouse/boomtest.db/tb_test/000000_0 [root@master boom]# ll 总用量 4 -rw-r--r--. 1 root root 10 5月 2 14:35 000000_0 [root@master boom]# cat 000000_0 1 dfdfddf [root@master boom]# |
同时,在mysql中的元数据截图:


5. 内置服务
执行bin/Hive --service help 如下:
|
[root@master shell]# /usr/program/hive/bin/hive --service help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cli help hiveburninclient hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool version Parameters parsed: --auxpath : Auxillary jars --config : Hive configuration directory --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: ./hive --service serviceName --help Debug help: ./hive --debug --help |
我们可以看到上边输出项Server List,里边显示出Hive支持的服务列表,beeline cli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat,下面介绍最有用的一些服务。
1、cli
这是Command Line Interface 的缩写,是Hive的命令行界面,用的比较多,是默认服务,直接可以在命令行里使用
2、hiveserver、hiveserver2:
这个可以让Hive以提供Thrift服务的服务器形式来运行,可以允许许多个不同语言编写的客户端进行通信,使用需要启动HiveServer或者HiveServer2服务以和客户端联系,我们可以通过环境变量或者运行时环境变量或者hive-site.xml来设置服务器所监听的端口,在默认情况下,端口号为10000,这个可以通过以下方式来启动:
由于hiveserver只支持单个客户端连接,所以通常情况下都使用hiveserver2
|
[root@master boom]# bin/hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001 |
两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,连这个和都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果(从hive0.15起就不再支持hiveserver了),HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,而HiveServer2却不会。既然已经存在HiveServer,为什么还需要HiveServer2呢?这是因为HiveServer不能处理多于一个客户端的并发请求,这是由于HiveServer使用的Thrift接口所导致的限制,不能通过修改HiveServer的代码修正。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供更好的支持。
3、hwi
其实就是hive web interface的缩写它是hive的web借口,是hive cli的一个web替代方案
4、jar
与Hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop 和Hive类的Java应用程序的简便方式
5、metastore
在默认的情况下,metastore和hive服务运行在同一个进程中,使用这个服务,可以让metastore作为一个单独的进程运行,也就是使用远端存储元数据时候需要使用该服务。我们可以通过METASTOE——PORT来指定监听的端口号
|
[root@master boom]# bin/hive --service metastore |
6. 启动方式
1、hive命令行模式
进入hive安装目录,输入bin/hive的执行程序,或者输入
hive –service cli
用于Linux平台命令行查询,查询语句基本跟MySQL查询语句类似
2、hive web界面的启动方式
bin/hive –service hwi (& 表示后台运行)
用于通过浏览器来访问hive,感觉没多大用途,浏览器访问地址是:
127.0.0.1:9999/hwi
3、hive 远程服务 (端口号10000)
bin/hive –service hiveserver2 &(&表示后台运行)
用java,Python等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了
7. Hiveserver2配置
Hiveserver2允许在配置文件hive-site.xml中进行配置管理,具体的参数为:
hive.server2.thrift.min.worker.threads– 最小工作线程数,默认为5。
hive.server2.thrift.max.worker.threads – 最小工作线程数,默认为500。
hive.server2.thrift.port– TCP 的监听端口,默认为10000。
hive.server2.thrift.bind.host– TCP绑定的主机,默认为localhost
也可以设置环境变量
HIVE_SERVER2_THRIFT_BIND_HOST和HIVE_SERVER2_THRIFT_PORT覆盖hive-site.xml设置的主机和端口号。从Hive-0.13.0开始,HiveServer2支持通过HTTP传输消息,该特性当客户端和服务器之间存在代理中介时特别有用。与HTTP传输相关的参数如下:
hive.server2.transport.mode – 默认值为binary(TCP),可选值HTTP。
hive.server2.thrift.http.port– HTTP的监听端口,默认值为10001。
hive.server2.thrift.http.path – 服务的端点名称,默认为 cliservice。
hive.server2.thrift.http.min.worker.threads– 服务池中的最小工作线程,默认为5。
hive.server2.thrift.http.max.worker.threads– 服务池中的最小工作线程,默认为500。
默认情况下,HiveServer2以提交查询的用户执行查询(true),如果hive.server2.enable.doAs设置为false,查询将以运行hiveserver2进程的用户运行。 为了防止非加密模式下的内存泄露,可以通过设置下面的参数为true禁用文件系统的缓存:
fs.hdfs.impl.disable.cache – 禁用HDFS文件系统缓存,默认值为false。
fs.file.impl.disable.cache – 禁用本地文件系统缓存,默认值为false。
http://blog.csdn.net/gamer_gyt/article/details/52062460
评论
发表评论
|
|
|