scala系列(十)高阶函数 有更新!
- 37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
- (一)高阶函数简介
- (二)Scala中的常用高阶函数
- map函数
- List类型
- Map类型
- flatMap函数
- filter函数
- reduce函数
- fold函数
- scan函数
- (三)SAM转换
- (四)函数柯里化
- (五)?部分应用函数
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
(一)高阶函数简介
高阶函数主要有两种:一种是将一个函数当做另外一个函数的参数(即函数参数);另外一种是返回值是函数的函数。这两种在本教程的第五节 函数与闭包中已经有所涉及,这里简单地回顾一下:
(1)函数参数
函数参数,即传入另一个函数的参数是函数
(2)返回值是函数的函数
高阶函数可以产生新的函数,即我们讲的函数返回值是一个函数
Scala中的高阶函数可以说是无处不在,这点可以在scala中的API文档中得到验证,下图给出的是Array数组的需要函数作为参数的API: 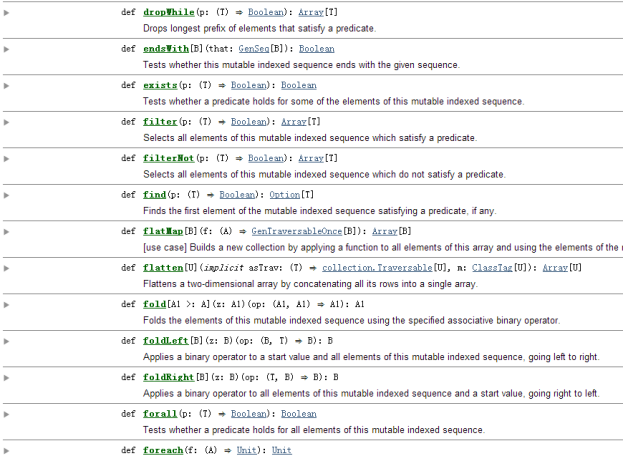
(二)Scala中的常用高阶函数
map函数
所有集合类型都存在map函数,例如Array的map函数的API具有如下形式:
|
def map[B](f: (A) ⇒ B): Array[B] 用途:Builds a new collection by applying a function to all elements of this array. B的含义:the element type of the returned collection. f的含义:the function to apply to each element. 返回:a new array resulting from applying the given function f to each element of this array and collecting the results. |
|
//这里面采用的是匿名函数的形式,字符串*n得到的是重复的n个字符串,这是scala中String操作的一个特点 scala> Array("spark","hive","hadoop").map((x:String)=>x*2) res3: Array[String] = Array(sparkspark, hivehive, hadoophadoop) //在函数与闭包那一小节,我们提到,上面的代码还可以简化 //省略匿名函数参数类型 scala> Array("spark","hive","hadoop").map((x)=>x*2) res4: Array[String] = Array(sparkspark, hivehive, hadoophadoop) //单个参数,还可以省去括号 scala> Array("spark","hive","hadoop").map(x=>x*2) res5: Array[String] = Array(sparkspark, hivehive, hadoophadoop) //参数在右边只出现一次的话,还可以用占位符的表示方式 scala> Array("spark","hive","hadoop").map(_*2) res6: Array[String] = Array(sparkspark, hivehive, hadoophadoop) |
List类型
|
scala> val list=List("Spark"->1,"hive"->2,"hadoop"->2) list: List[(String, Int)] = List((Spark,1), (hive,2), (hadoop,2)) //写法1 scala> list.map(x=>x._1) res20: List[String] = List(Spark, hive, hadoop) //写法2 scala> list.map(_._1) res21: List[String] = List(Spark, hive, hadoop) scala> list.map(_._2) res22: List[Int] = List(1, 2, 2) |
Map类型
|
//写法1 scala> Map("spark"->1,"hive"->2,"hadoop"->3).map(_._1) res23: scala.collection.immutable.Iterable[String] = List(spark, hive, hadoop) scala> Map("spark"->1,"hive"->2,"hadoop"->3).map(_._2) res24: scala.collection.immutable.Iterable[Int] = List(1, 2, 3) //写法2 scala> Map("spark"->1,"hive"->2,"hadoop"->3).map(x=>x._2) res25: scala.collection.immutable.Iterable[Int] = List(1, 2, 3) scala> Map("spark"->1,"hive"->2,"hadoop"->3).map(x=>x._1) res26: scala.collection.immutable.Iterable[String] = List(spark, hive, hadoop) |
flatMap函数
|
//写法1 scala> List(List(1,2,3),List(2,3,4)).flatMap(x=>x) res40: List[Int] = List(1, 2, 3, 2, 3, 4) //写法2 scala> List(List(1,2,3),List(2,3,4)).flatMap(x=>x.map(y=>y)) res41: List[Int] = List(1, 2, 3, 2, 3, 4) |
filter函数
|
scala> Array(1,2,4,3,5).filter(_>3) res48: Array[Int] = Array(4, 5) scala> List("List","Set","Array").filter(_.length>3) res49: List[String] = List(List, Array) scala> Map("List"->3,"Set"->5,"Array"->7).filter(_._2>3) res50: scala.collection.immutable.Map[String,Int] = Map(Set -> 5, Array -> 7) |
reduce函数
|
//写法1 scala> Array(1,2,4,3,5).reduce(_+_) res51: Int = 15 scala> List("Spark","Hive","Hadoop").reduce(_+_) res52: String = SparkHiveHadoop //写法2 scala> Array(1,2,4,3,5).reduce((x:Int,y:Int)=>{println(x,y);x+y}) (1,2) (3,4) (7,3) (10,5) res60: Int = 15 scala> Array(1,2,4,3,5).reduceLeft((x:Int,y:Int)=>{println(x,y);x+y}) (1,2) (3,4) (7,3) (10,5) res61: Int = 15 scala> Array(1,2,4,3,5).reduceRight((x:Int,y:Int)=>{println(x,y);x+y}) (3,5) (4,8) (2,12) (1,14) res62: Int = 15 |
fold函数
|
scala> Array(1,2,4,3,5).foldLeft(0)((x:Int,y:Int)=>{println(x,y);x+y}) (0,1)(1,2)(3,4)(7,3)(10,5) res66: Int = 15 scala> Array(1,2,4,3,5).foldRight(0)((x:Int,y:Int)=>{println(x,y);x+y}) (5,0)(3,5)(4,8)(2,12)(1,14) res67: Int = 15 scala> Array(1,2,4,3,5).foldLeft(0)(_+_) res68: Int = 15 scala> Array(1,2,4,3,5).foldRight(10)(_+_) res69: Int = 25 // /:相当于foldLeftscala> (0 /: Array(1,2,4,3,5)) (_+_)res70: Int = 15 scala> (0 /: Array(1,2,4,3,5)) ((x:Int,y:Int)=>{println(x,y);x+y}) (0,1)(1,2)(3,4)(7,3)(10,5) res72: Int = 15 |
scan函数
|
//从左扫描,每步的结果都保存起来,执行完成后生成数组 scala> Array(1,2,4,3,5).scanLeft(0)((x:Int,y:Int)=>{println(x,y);x+y}) (0,1)(1,2)(3,4)(7,3)(10,5) res73: Array[Int] = Array(0, 1, 3, 7, 10, 15) //从右扫描,每步的结果都保存起来,执行完成后生成数组 scala> Array(1,2,4,3,5).scanRight(0)((x:Int,y:Int)=>{println(x,y);x+y}) (5,0)(3,5)(4,8)(2,12)(1,14) res74: Array[Int] = Array(15, 14, 12, 8, 5, 0) |
(三)SAM转换
在Java的GUI编程中,在设置某个按钮的监听器的时候,我们常常会使用下面的代码(利用scala进行代码开发):
|
var counter=0; val button=new JButton("click") button.addActionListener(new ActionListener{ override def actionPerformed(event:ActionEvent){ counter+=1 } }) |
上面代码在addActionListener方法中定义了一个实现了ActionListener接口的匿名内部类,代码中
|
override def actionPerformed(event:ActionEvent){ counter+=1 } |
这部分称为样板代码,即在任何实现该接口的类中都需要这样用,重复性较高,由于ActionListener接口只有一个actionPerformed方法,它被称为simple abstract method(SAM)。SAM转换是指只给addActionListener方法传递一个参数
|
button.addActionListener((event:ActionEvent)=>counter+=1) //并提供一个隐式转换,我们后面会具体讲隐式转换 implict def makeAction(action:(event:ActionEvent)=>Unit){ new ActionListener{ override def actionPerformed(event:ActionEvent){action(event)} } |
这样的话,在进行GUI编程的时候,可以省略非常多的样板代码,使代码更简洁。
(四)函数柯里化
http://blog.csdn.net/lovehuangjiaju/article/details/47079383
在函数与闭包那一节中,我们定义了下面这样的一个函数
//mutiplyBy这个函数的返回值是一个函数//该函数的输入是Doulbe,返回值也是Double
scala> def multiplyBy(factor:Double)=(x:Double)=>factor*x
multiplyBy: (factor: Double)Double => Double
//返回的函数作为值函数赋值给变量x
scala> val x=multiplyBy(10)
x: Double => Double = <function1>
//变量x现在可以直接当函数使用
scala> x(50)
res33: Double = 500.0
上述代码可以像这样使用:
scala> def multiplyBy(factor:Double)=(x:Double)=>factor*xmultiplyBy: (factor: Double)Double => Double
//这是高阶函数调用的另外一种形式
scala> multiplyBy(10)(50)res77: Double = 500.0
那函数柯里化(curry)是怎么样的呢?其实就是将multiplyBy函数定义成如下形式
scala> def multiplyBy(factor:Double)(x:Double)=x*factor
multiplyBy: (factor: Double)(x: Double)Double
2
即通过(factor:Double)(x:Double)定义函数参数,该函数的调用方式如下:
//柯里化的函数调用方式
scala> multiplyBy(10)(50)
res81: Double = 500.0
//但此时它不能像def multiplyBy(factor:Double)=(x:Double)=>factor*x函数一样,可以输入单个参数进行调用
scala> multiplyBy(10)
<console>:10: error: missing arguments for method multiplyBy;
follow this method with `_' if you want to treat it as a partially applied function
multiplyBy(10)
^
12
错误提示函数multiplyBy缺少参数,如果要这么做的话,需要将其定义为偏函数
scala> multiplyBy(10)_
res79: Double => Double = <function1>
2
那现在我们接着对偏函数进行介绍
(五)?部分应用函数
在数组那一节中,我们讲到,Scala中的数组可以通过foreach方法将其内容打印出来,代码如下:
scala>Array("Hadoop","Hive","Spark")foreach(x=>println(x))
Hadoop
Hive
Spark//上面的代码等价于下面的代码
scala> def print(x:String)=println(x)print: (x: String)Unit
scala> Array("Hadoop","Hive","Spark")foreach(print)
Hadoop
Hive
Spark
11
12
那什么是部分应用函数呢,所谓部分应用函数就是指,当函数有多个参数,而在我们使用该函数时我们不想提供所有参数(假设函数有3个函数),只提供0~2个参数,此时得到的函数便是部分应用函数,定义上述print函数的部分应用函数代码如下:
//定义print的部分应用函数
scala> val p=print _
p: String => Unit = <function1>
scala> Array("Hadoop","Hive","Spark")foreach(p)
Hadoop
Hive
Spark
scala> Array("Hadoop","Hive","Spark")foreach(print _)
Hadoop
Hive
Spark
12
13
14
在上面的简化输出代码中,下划线_并不是占位符的作用,而是作为部分应用函数的定义符。前面我演示了一个参数的函数部分应用函数的定义方式,现在我们定义一个多个输入参数的函数,代码如下:
//定义一个求和函数
scala> def sum(x:Int,y:Int,z:Int)=x+y+zsum: (x: Int, y: Int, z: Int)Int
//不指定任何参数的部分应用函数
scala> val s1=sum _
s1: (Int, Int, Int) => Int = <function3>
scala> s1(1,2,3)
res91: Int = 6
//指定两个参数的部分应用函数
scala> val s2=sum(1,_:Int,3)
s2: Int => Int = <function1>
scala> s2(2)
res92: Int = 6
//指定一个参数的部分应用函数
scala> val s3=sum(1,_:Int,_:Int)
s3: (Int, Int) => Int = <function2>
scala> s3(2,3)
res93: Int = 6
22
23
24
在函数柯里化那部分,我们提到柯里化的multiplyBy函数输入单个参数,它并不会像没有柯里化的函数那样返回一个函数,而是会报错,如果需要其返回函数的话,需要定义其部分应用函数,代码如下:
//定义multiplyBy函数的部分应用函数,它返回的是一个函数
scala> val m=multiplyBy(10)_
m: Double => Double = <function1>
scala> m(50)
res94: Double = 500.0
评论
发表评论
|
|
|