linux常用命令(二) 有更新!
- grep
- 1. 常用
- 2. grep -c 'boom'f2 统计个数
- 3. grep -i 'boom' f2 忽略大小
- 4. grep -n 'boom' f2 显示行号
- 5. grep -v 'boom'f2 反向选择
- 6. dmesg | grep -n 'eth' 配合管道使用
- 7. dmesg | grep -n -A 1 -B 1 'eth'显示关键字前N行和后M行
- 8. grep 'boom' * 目录下搜索所有文件
- 9. grep -r 'boom' * 递归搜索当前目录下所有文件
- 正则grep
- 1. 文档内容:
- 2. grep oom f3
- 3. grep '[ab]oom' f3
- 4. grep '[a-z]oom' f3
- 5. grep '[a-z]oom$' f3
- 6. grep '^oom' f3
- 7. grep '^oom$' f3
- 8. grep "aoom\\|coom" f3
- 9. . 与 *
- a) grep "m.d" f3
- b) grep "m..d" f3
- c) grep "m*d" f3
- d) grep "m.*d" f3
- e) grep "m..*d" f3
- f) grep "m[a-z][a-z]*d" f3
- 10. s{m,n} 连续限定符
- a) grep "m[a-z]\\{1,3\\}d" f3
- b) grep "m[a-z]\\{1,\\}d" f3
- 11. cat ./boom/redis-3.0.7/redis.conf | grep -v "#\\|^$"
- sed
- man
- alias、which、source
- 1. which cp
- 2. alias 查看所有别名
- 3. alias xiaoben = 'echo "I am xiaoben!"'定义别名
- 4. unalias xiaoben 解绑别名
- 5. vi ~/.bashrc 永久生效
- 6. source ~/.bashrc
- find
- 1. find ./ -type f -name *.txt 按文件名
- 2. find ./ -type f -name 'ssh_*' 按文件名模糊搜索
- 3. find ./ -type f -mtime -5 按修改时间(-n最近n天)
- 4. find ./ -type f -name *.txt -fprint res.log
- 5. find -type f -name *.txt -o -name *.log
- 6. 其它
- 7. xargs
- find | xargs cat
- 按行分隔删除redis key
- 其它示例
- awk
- 使用方法
- 内置变量
- last -n 5
- last -n 5 | awk '{print $1}'
- head -5 /etc/passwd |awk -F ':' '{print $1"\t"$7}'
- head -5 /etc/passwd |awk -F ':' 'BEGIN {print "name\tshell"}{print $1"\t"$7}
- awk -F: '/root/' /etc/passwd
- ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024, "M" "."}'
- awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
- uname
- diff、vimdiff
- diff a.txt b.txt
- vimdiff a.txt b.txt
- whoami
- useradd、passwd
- history
- su su-
grep
1. 常用
[root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
|
[root@master test]# grep 'boom' f2 boom boomx2 boomhah haboom boom23 2boom3 |
2. grep -c 'boom'f2 统计个数
|
[root@master test]# grep -c boom f2 6 |
3. grep -i 'boom' f2 忽略大小
|
[root@master test]# grep -i 'boom' f2 boom boomx2 boomhah haboom boom23 2boom3 BooM |
4. grep -n 'boom' f2 显示行号
|
[root@master test]# grep -n 'boom' f2 1:boom 2:boomx2 6:boomhah 7:haboom 12:boom23 13:2boom3 |
5. grep -v 'boom'f2 反向选择
|
[root@master test]# grep -v boom f2 hehe haha nihao xasd fdfd 232 fdg BooM |
6. dmesg | grep -n 'eth' 配合管道使用
--color=auto显示关键字
|
[root@master test]# dmesg | grep -n --color=auto 'eth' 1384:eth0: registered as PCnet/PCI II 79C970A 1404:eth0: link up 1405:eth0: no IPv6 routers present |
7. dmesg | grep -n -A 1 -B 1 'eth'显示关键字前N行和后M行
-B, --before-context=NUM print NUM lines of leading context 前面几行
-A, --after-context=NUM print NUM lines of trailing context 后面几行
|
[root@master test]# dmesg | grep -n -A 1 -B 1 --color=auto 'eth' 1383-pcnet32: PCnet/PCI II 79C970A at 0x2000, 00:0c:29:e2:c6:cf assigned IRQ 19. 1384:eth0: registered as PCnet/PCI II 79C970A 1385-pcnet32: 1 cards_found. -- 1403-SELinux: initialized (dev autofs, type autofs), uses genfs_contexts 1404:eth0: link up 1405:eth0: no IPv6 routers present 1406-hrtimer: interrupt took 3705869 ns [root@master test]# |
8. grep 'boom' * 目录下搜索所有文件
|
[root@master test]# grep 'boom' * f2:boom f2:boomx2 f2:haboom f2:2boom3 f3:boom124 f3:boom343 [root@master test]# |
9. grep -r 'boom' * 递归搜索当前目录下所有文件
|
[root@master test]# grep -r 'boom' * d2/dt.txt:boom d2/dt.txt:ssboomss d2/dt.txt:boomsdf f2:boom f2:boomx2 f2:haboom f2:2boom3 f3:boom124 f3:boom343 [root@master test]# |
正则grep
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html
常用示例:
1. 文档内容:
|
[root@master test]# cat f3 boom aoom dsdf pinkboomfff pinkboom coom123 oom oomcdd oomssd dfdf [root@master test]# |
2. grep oom f3
包含oom的行
|
[root@master test]# grep oom f3 boom aoom pinkboomfff pinkboom coom123 oom oomcdd oomssd |
3. grep '[ab]oom' f3
包含aoom或者boom的行
|
[root@master test]# grep '[ab]oom' f3 boom aoom pinkboomfff pinkboom |
4. grep '[a-z]oom' f3
包含aoom或者boom... zoom 的行
|
[root@master test]# grep '[a-z]oom' f3 boom aoom pinkboomfff pinkboom coom123 |
5. grep '[a-z]oom$' f3
以[a-z]oom结尾的行
|
[root@master test]# grep '[a-z]oom$' f3 boom aoom pinkboom |
6. grep '^oom' f3
以oom开头的行
|
[root@master test]# grep '^oom' f3 oom oomcdd oomssd |
7. grep '^oom$' f3
以oom开头并且以oom结尾的行,就是行=oom的行
|
[root@master test]# grep '^oom$' f3 oom |
8. grep "aoom\\|coom" f3
包含aoom 或者coom的行,注意单引号 与 双引号的差别。
|
[root@master test]# grep 'aoom|coom' f3 [root@master test]# grep 'aoom\\|coom' f3 [root@master test]# grep "aoom\\|coom" f3 aoom coom123 |
9. . 与 *
. (小数点):代表『一定有一个任意字节』的意思;
* (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
|
[root@master test]# cat f3 boom aoom dsdf pinkboomfff pinkboom coom123 oom oomcdd oomssd dfdf ombd omdfeee omdxxxxxxxxxd |
a) grep "m.d" f3
|
[root@master test]# grep "m.d" f3 oomcdd ombd |
b) grep "m..d" f3
|
[root@master test]# grep "m..d" f3 oomcdd oomssd |
c) grep "m*d" f3
这个匹配并不是匹配md中间任意字符,而是匹配包含d或者md ,mmd,*md的行,如下图:
|
[root@master test]# grep "m*d" f3 dsdf oomcdd oomssd dfdf ombd omdfeee omdxxxxxxxxxd |
d) grep "m.*d" f3
匹配包含md中间任意字符(0个或N个任意字符)
|
[root@master test]# grep "m*d" f3 | grep -v "md" dsdf oomcdd oomssd dfdf ombd |
e) grep "m..*d" f3
匹配包含md中间至少1个任意字符以上(1个或N个任意字符)的行
|
[root@master test]# grep "m..*d" f3 oomcdd oomssd ombd omdxxxxxxxxxd |
f) grep "m[a-z][a-z]*d" f3
匹配包含md中间至少1个小写字母以上(1个或N个小写字符)的行
|
[root@master test]# cat f3 boom aoom dsdf pinkboomfff pinkboom coom123 oom oomcdd oomssd dfdf ombd omdfeee omdxxxxxxxxxd om22d [root@master test]# grep "m[a-z][a-z]*d" f3 oomcdd oomssd ombd omdxxxxxxxxxd [root@master test]# |
10. s{m,n} 连续限定符
a) grep "m[a-z]\\{1,3\\}d" f3
匹配包含(md中间有1到3个字母)的字符串的行
|
[root@master test]# grep "m[a-z]\\{1,3\\}d" f3 oomcdd oomssd ombd |
b) grep "m[a-z]\\{1,\\}d" f3
匹配包含(md中间有1到无限个字母)的字符串的行
|
[root@master test]# grep "m[a-z]\\{1,\\}d" f3 oomcdd oomssd ombd omdxxxxxxxxxd [root@master test]# |
11. cat ./boom/redis-3.0.7/redis.conf | grep -v "#\\|^$"
排除注释与空行
|
[root@localhost ~]# cat ./boom/redis-3.0.7/redis.conf | grep -v "#\\|^$" daemonize no pidfile /var/run/redis.pid port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 0 loglevel debug logfile "" databases 16 save 900 1 save 300 10 save 60 10000 |
sed
sed - stream editor for filtering and transforming text
Sed is a stream editor. A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline). While in some ways similar to an editor which permits scripted edits (such as ed), sed works by making only one pass over the input(s), and is consequently more efficient. But it is sed’s ability to filter text in a pipeline which particularly distinguishes it from other types of editors.
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856901.html
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
[root@www ~]# sed [-nefr] [动作]
选项与参数:-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。-e :直接在命令列模式上进行 sed 的动作编辑;-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)-i :直接修改读取的文件内容,而不是输出到终端。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
|
[root@www ~]# nl /etc/passwd | sed '2,5d' 1 root 6 sync 7 shutdown .....(后面省略)..... |
 0:0:root:/root:/bin/bash
0:0:root:/root:/bin/bash要删除第 3 到最后一行
|
nl /etc/passwd | sed '3,$d' |
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
|
[root@www ~]# nl /etc/passwd | sed '2a drink tea' 1 root 2 bin drink tea 3 daemon .....(后面省略)..... |
man
查看命令帮助
按q退出
Tab 单机 双击 提示
alias、which、source
1. which cp
|
[root@master test]# which cp alias cp='cp -i' /bin/cp |
2. alias 查看所有别名
|
[root@master test]# alias alias cp='cp -i' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias mv='mv -i' alias rm='rm -i' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' [root@master test]# |
3. alias xiaoben = 'echo "I am xiaoben!"'定义别名
|
[root@master test]# alias xiaoben = 'echo "I am xiaoben!"' -bash: alias: xiaoben: not found -bash: alias: =: not found -bash: alias: echo "I am xiaoben!": not found [root@master test]# alias xiaoben='echo "I am xiaoben!"' [root@master test]# xiaoben I am xiaoben! |
4. unalias xiaoben 解绑别名
|
[root@master test]# unalias xiaoben [root@master test]# xiaoben -bash: xiaoben: command not found |
5. vi ~/.bashrc 永久生效
|
[root@master test]# vi ~/.bashrc # .bashrc # User specific aliases and functions alias rm='rm -i' alias cp='cp -i' alias mv='mv -i' alias xiaoben='echo "hello!xiaoben."' |
6. source ~/.bashrc
即时生效配置
|
[root@master test]# xiaoben -bash: xiaoben: command not found [root@master test]# source ~/.bashrc [root@master test]# xiaoben hello!xiaoben. |
find
find - search for files in a directory hierarchy
-name filename #查找名为filename的文件
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查GIN: 0px">
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup 查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-newer f1 !f2 #查更改时间比f1新但比f2旧的文件
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-depth #使查找在进入子目录前先行查找完本目录
-fstype #查更改时间比f1新但比f2旧的文件
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-depth #使查找在进入子目录前先行查找完本目录
-fstype #查位于某一类型文件系统中的文件,这些文件系统类型通常可在/etc/fstab中找到
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-cpio %; #查位于某一类型文件系统中的文件,这些文件系统类型通常可在/etc/fstab中找到
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-cpio #对匹配的文件使用cpio命令,将他们备份到磁带设备中
-prune #忽略某个目录
1. find ./ -type f -name *.txt 按文件名
|
[root@master test]# find ./ -type f -name nbsp;*.txt ./d2/dt.txt [root@master test]# |
2. find ./ -type f -name 'ssh_*' 按文件名模糊搜索
最好都带上引号’’。否则有可能搜索不到。
|
[root@master etc]# find ./ -type f -name 'ssh_*' ./ssh/ssh_host_rsa_key.pub ./ssh/ssh_host_rsa_key ./ssh/ssh_host_dsa_key.pub ./ssh/ssh_config ./ssh/ssh_host_key.pub ./ssh/ssh_host_dsa_key ./ssh/ssh_host_key [root@master etc]# |
3. find ./ -type f -mtime -5 按修改时间(-n最近n天)
|
[root@master test]# find ./ -type f -mtime -5 ./f3 ./d2/dt.txt ./f2 |
4. find ./ -type f -name *.txt -fprint res.log
搜索结果输出到文件中
|
[root@master test]# find ./ -type f -name *.txt -fprint res.log [root@master test]# ls d2 d3 f2 f3 res.log |
5. find -type f -name *.txt -o -name *.log
查找以.txt 和 .log结尾的文件
|
[root@master test]# find -type f -name *.txt -o -name *.log ./d2/dt.txt ./res.log |
6. 其它
find /mnt -name tom.txt -ftype vfat 在/mnt下查找名称为tom.txt且文件系统类型为vfat的文件
find /mnt -name tom.txt ! -ftype vfat 在/mnt下查找名称为tom.txt且文件系统类型不为vfat的文件
find /home -atime -1 查1天之内被存取过的文件
find /home -mmin +60 在/home下查60分钟前改动过的文件
find /home -amin +30 查最近30分钟前被存取过的文件
find /home -newer tmp.txt 在/home下查更新时间比tmp.txt近的文件或目录
find /home -anewer tmp.txt 在/home下查存取时间比tmp.txt近的文件或目录
find /home -used -2 列出文件或目录被改动过之后,在2日内被存取过的文件或目录
find /home -user cnscn 列出/home目录内属于用户cnscn的文件或目录
find /home -uid +501 列出/home目录内用户的识别码大于501的文件或目录
find /home -group cnscn 列出/home内组为cnscn的文件或目录
find /home -gid 501 列出/home内组id为501的文件或目录
find /home -nouser 列出/home内不属于本地用户的文件或目录
find /home -nogroup 列出/home内不属于本地组的文件或目录
find /home -name tmp.txt -maxdepth 4 列出/home内的tmp.txt 查时深度最多为3层
find /home -name tmp.txt -mindepth 3 从第2层开始查
find /home -empty 查找大小为0的文件或空目录
find /home -size +512k 查大于512k的文件
find /home -size -512k 查小于512k的文件
find /home -links +2 查硬连接数大于2的文件或目录
find /home -perm 0700 查权限为700的文件或目录
find /tmp -name tmp.txt -exec cat {} \;
find /tmp -name tmp.txt -ok rm {} \;
find / -amin -10 # 查找在系统中最后10分钟访问的文件
find / -atime -2 # 查找在系统中最后48小时访问的文件
find / -empty # 查找在系统中为空的文件或者文件夹
find / -group cat # 查找在系统中属于 groupcat的文件
find / -mmin -5 # 查找在系统中最后5分钟里修改过的文件
find / -mtime -1 #查找在系统中最后24小时里修改过的文件
find / -nouser #查找在系统中属于作废用户的文件
find / -user fred #查找在系统中属于FRED这个用户的文件
7. xargs
xargs - build and execute command lines from standard input
find | xargs cat
|
[root@master test]# find -type f -name *.txt -o -name *.log | cat ./d2/dt.txt ./res.log |
打印出查找的文件内容
|
[root@master test]# find -type f -name *.txt -o -name *.log | xargs cat boom ssboomss asdf ddfd boomsdf ./d2/dt.txt |
按行分隔删除redis key
cat data2.txt | xargs -i redis-cli -a dada123 DEL {}
|
au_2750571 au_2805049 au_1953523 au_2765705 au_2805048 au_2805150 au_2805165 au_2805169 |
|
[root@localhost xboom]# cat data2.txt | xargs -i redis-cli -a dada123 DEL {} |
其它示例
1、在当前目录下查找所有用户具有读、写和执行权限的文件,并收回相应的写权限:
# find . -perm -7 -print | xargs chmod o-w
2、查找系统中的每一个普通文件,然后使用xargs命令来测试它们分别属于哪类文件
# find . -type f -print | xargs file
./liyao: empty
3、尝试用rm 删除太多的文件,你可能得到一个错误信息:/bin/rm Argument list too long. 用xargs 去避免这个问题
$find ~ -name ‘*.log’ -print0 | xargs -i -0 rm -f {}
4、查找所有的jpg 文件,并且压缩它
# find / -name *.jpg -type f -print | xargs tar -cvzf images.tar.gz
5、拷贝所有的图片文件到一个外部的硬盘驱动
# ls *.jpg | xargs -n1 -i cp {} /external-hard-drive/directory
awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
内置变量
|
RGC |
命令行参数个数 |
NF |
浏览记录的域个数 |
|
AGRV |
命令行参数排列 |
NR |
已读的记录数 |
|
ENVIRON |
支持队列中系统环境变量的使用 |
OFS |
输出域分隔符 |
|
FILENAME |
awk浏览的文件名 |
ORS |
输出记录分隔符 |
|
FNR |
浏览文件的记录数 |
RS |
控制记录分隔符 |
|
FS |
设置输入域分隔符,同- F选项 |
|
|
last -n 5
|
[root@master ~]# last -n 5 root pts/0 192.168.187.69 Wed Jan 25 13:19 still logged in root tty1 Wed Jan 25 13:18 still logged in reboot system boot 2.6.32-431.el6.x Wed Jan 25 11:20 - 13:26 (02:05) root pts/0 192.168.187.69 Mon Jan 23 20:42 - crash (1+14:38) root pts/0 192.168.187.69 Mon Jan 23 17:57 - 20:36 (02:39) wtmp begins Mon Sep 19 17:22:27 2016 |
last -n 5 | awk '{print $1}'
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
|
[root@master ~]# last -n 5 | awk '{print $1}' root root reboot root root wtmp [root@master ~]# |
|
[root@master ~]# last -n 5 | awk '{print $3}' 192.168.187.69 Wed boot 192.168.187.69 192.168.187.69 Mon [root@master ~]# |
head -5 /etc/passwd |awk -F ':' '{print $1"\t"$7}'
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
只是显示/etc/passwd的账户和账户对应的shell,之间以tab键分割
|
[root@master ~]# head -5 /etc/passwd |awk -F ':' '{print $1"\t"$7}' root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin [root@master ~]# |
head -5 /etc/passwd
|
[root@master ~]# head -5 /etc/passwd root bin daemon adm lp [root@master ~]# |
head -5 /etc/passwd |awk -F ':' 'BEGIN {print "name\tshell"}{print $1"\t"$7}
在所有行添加列名name,shell,并以\t分割。
|
[root@master ~]# head -5 /etc/passwd |awk -F ':' 'BEGIN {print "name\tshell"}{print $1"\t"$7}' name shell root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin [root@master ~]# |
执行流程:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
awk -F: '/root/' /etc/passwd
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。以’//’包含的pattern表达式。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
|
[root@master ~]# awk -F: '/root/' /etc/passwd root operator |
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024, "M" "."}'
统计某个文件夹下的文件占用的字节数
|
[root@master test]# ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024, "M" "."}' [end]size is 2.48018 M. |
过滤4096大小的文件(一般都是文件夹):
|
[root@master test]# ls -l |awk 'BEGIN {size=0;print "[start]size is ", size} {if($5!=4096){size=size+$5;}} END{print "[end]size is ", size/1024/1024,"M"}' [start]size is 0 [end]size is 2.47237 M |
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
循环
|
[root@master test]# awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd 0 root 1 bin 2 daemon 3 adm |
uname
-s, --kernel-name print the kernel name
-n, --nodename print the network node hostname
-r, --kernel-release print the kernel release
-v, --kernel-version print the kernel version
-m, --machine print the machine hardware name
-p, --processor print the processor type or "unknown"
-i, --hardware-platform print the hardware platform or "unknown"
-o, --operating-system print the operating syste
系统信息查看
|
[root@master test]# uname -r 2.6.32-431.el6.x86_64 [root@master test]# uname -m x86_64 [root@master test]# uname -a Linux master 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux [root@master test]# |
diff、vimdiff
diff a.txt b.txt
可以比较,但是不直观。
|
[root@master test]# diff a.txt b.txt 1,2c1,2 < 123 < 123456 --- > 1234 > 123856 7c7 < asdfasdfasd --- > asdfbsdfasd 9a10 > 23423 |
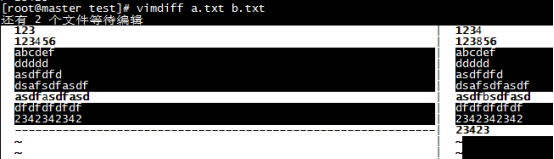
vimdiff a.txt b.txt
|
[root@master test]# vimdiff a.txt b.txt 还有 2 个文件等待编辑 |
whoami
|
[root@master test]# whoami root [root@master test]# |
useradd、passwd
|
[root@master test]# useradd boom [root@master test]# passwd boom 更改用户 boom 的密码 。 新的 密码: 无效的密码: 过于简单化/系统化 无效的密码: 过于简单 重新输入新的 密码: passwd: 所有的身份验证令牌已经成功更新。 [root@master test]# |
$普通用户,#超级管理员
|
[boom@master root]$ [boom@master root]$ exit exit [root@master ~]# [root@master ~]# [root@master ~]# |
history
history –d 行号 删除历史记录
history –c 删除所有历史记录
su su-
切换用户
su命令和su -命令最大的本质区别就是:前者只是切换了root身份,但Shell环境仍然是普通用户的Shell;而后者连用户和Shell环境一起切换成root身份了。只有切换了Shell环境才不会出现PATH环境变量错误。su切换成root用户以后,pwd一下,发现工作目录仍然是普通用户的工作目录;而用su -命令切换以后,工作目录变成root的工作目录了。用echo $PATH命令看一下su和su -以后的环境变量有何不同。以此类推,要从当前用户切换到其它用户也一样,应该使用su -命令。
|
[boom@master ~]$ su - root 密码: [root@master ~]# pwd /root |
|
[boom@master ~]$ su 密码: [root@master boom]# pwd /home/boom [root@master boom]# |
尽量使用su - 切换用户
评论
发表评论
|
|
|