scala系列(八)Scala类层次结构、Traits 有更新!
- 37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
- (一)Scala类层次结构
- (二)Scala中原生类型的实现方式解析
- (三)Nothing、Null类型解析
- (四)Traits简介
- (五)Traits几种不同使用方式
- 1. 当做java接口使用的trait
- 2. 带具体实现的trait
- 3. 带抽象字段的trait
- 4. 具体字段的trait
- (六)trait构造顺序
- (七)trait与类的比较
- (八)提前定义与懒加载
- 1. 提前定义
- 2. lazy懒加载的方式
- (九)trait扩展类
- (十)self type
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
(一)Scala类层次结构
Scala中的类层次结构图如下:

从上面的类层次结构图中可以看到,处于继承层次最顶层的是Any类,它是scala继承的根类,scala中所有的类都是它的子类
Any类中定义了下面几个方法:
|
//==与!=被声明为final,它们不能被子类重写 final def ==(that: Any): Boolean final def !=(that: Any): Boolean def equals(that: Any): Boolean def hashCode: Int def toString: String |
从上面的代码看可以看到,Any类中共包括了五个方法,其中==与!=被声明为final类型的,因此它们不能被子类重写,事实上==的真正实现是通过equals方法来实现的,而!=是通过!equals来实现的,因此如果想改变==与!=方法的行为的话,可以直接对equals进行重写。
根类Any有两个子类,它们分别是AnyVal和AnyRef,其中AnyVal是所有scala内置的值类型( Byte, Short, Char, Int, Long, Float, Double, Boolean, Unit.)的父类,其中 Byte, Short, Char, Int, Long, Float, Double, Boolean与Java中的byte,short,char,int,long,float,double,boolean原生类型对应,而Unit对应java中的void类型,由于( Byte, Short, Char, Int, Long, Float, Double, Boolean, Unit)继承AnyVal,而AnyVal又继承Any,因此它们也可以调用toString等方法。
|
scala> 2.0.hashCoderes5: Int = 1073741824 scala> 2.0 toStringres6: String = 2.0 |
值得一提的是,()可以作为Unit类型的实例,它同样可以调用toString等方法
|
def main(args: Array[String]): Unit = { println(().hashCode()) println(().toString()) println(()==()) } |
|
0 () true |
AnyRef是Any的另外一个子类,它是scala中所有非值类型的父类,对应Java.lang.Object类(可以看作是java.lang.Object类的别名),也即它是所有引用类型的父类(除值类型外)。那为什么不直接Java.lang.Object作为scala非值引用类型的父类呢?这是因为Scala还可以运行在其它平台上如.Net,所以它使用了AnyRef这个类,在JVM上它对应的是java.lang.Object,而对于其它平台有不同的实现。
(二)Scala中原生类型的实现方式解析
scala采用与java相同原生类型存储方式,由于性能方面及与java进行操作方面的考虑,scala对于原生类型的基本操作如加减乘除操作与java是一样的,当需要遇到其他方法调用时,则使用java的原生类型封装类来表示,如Int类型对应于java.lang.Integer类型,这种转换对于我们使用者来说是透明的。
在本课程的第二节中我们提到,scala中的==操作它不区分你是原生类型还是引用类型,例如
|
println("abc"=="abc") |
|
true |
如果是在java语言中,它返回的是false。在scala中,对于原生类型,这种等于操作同java原生类型,而对于引用类型,它实际上是用equals方法对==方法进行实现,这样避免了程序设计时存在的某些问题。那如果想判断两个引用类型是否相等时怎么办呢? AnyRef中提供了eq、ne两个方法用于判断两个引用是否相等,如
|
var a1 = "abc"; var a2 = "abc"; println(a1 == a2) println(a1.eq(a2)) println(a1.ne(a2)) |
|
true true false |
(三)Nothing、Null类型解析
在前面的类层次结构图中可以看到,Null类型是所有AnyRef类型的子类型,也即它处于AnyRef类的底层,对应java中的null引用。而Nothing是scala类中所有类的子类,它处于scala类的最底层。
这里面必须注意的是Null类型处于AnyRef类的底层,它不能够作为值类型的子类,例如:
|
scala> var x:Int=null <console>:7: error: type mismatch; found : Null(null) required: Int Note that implicit conversions are not applicable because they are ambiguous: both method Integer2intNullConflict in class LowPriorityImplicits of type (x: N ull)Int and method Integer2int in object Predef of type (x: Integer)Int are possible conversion functions from Null(null) to Int var x:Int=null ^ |
Nothing这个类一般用于指示程序返回非正常结果,利用Nothing作为返回值可以增加程序的灵活性。例如:
|
def error(msg:String):Nothing={ throw new RuntimeException(msg) } def divide(x: Int, y: Int): Int = if (y != 0) x / y else error("can't divide by zero") } |
(四)Traits简介
scala和java语言一样,采用了很强的限制策略,避免了多种继承的问题。在java语言中,只允许继承一个超类,该类可以实现多个接口,但java接口有其自身的局限性:接口中只能包括抽象方法,不能包含字段、具体方法。Scala语言利用Trait解决了该问题,在scala的trait中,它不但可以包括抽象方法还可以包含字段和具体方法。trait的示例如下:
生成的字节码文件反编译后的结果:
|
public abstract interface DAO { public abstract boolean delete(String paramString); public abstract boolean add(Object paramObject); public abstract int update(Object paramObject); public abstract List<Object> query(String paramString); } |
下面的代码演示了如何使用trait
|
trait MysqlDAO{ def add(o:Any):Boolean def update(o:Any):Int def query(id:String):List[Any] } class DaoImpl extends MysqlDAO{ def add(o:Any):Boolean=true def update(o:Any):Int= 1 def query(id:String):List[Any]=List(1,2,3)
} |
如果有多个trait的话:
|
trait MysqlDAO{ var recodeMount:Long=15000000000000L def add(o:Any):Boolean def update(o:Any):Int def query(id:String):List[Any] } class DaoImpl extends MysqlDAO with Cloneable{ def add(o:Any):Boolean=true def update(o:Any):Int= 1 def query(id:String):List[Any]=List(1,2,3)
} |
(五)Traits几种不同使用方式
1. 当做java接口使用的trait
|
//trait定义演示 trait DAO{ //定义一个抽象方法,注意不需要加abstract //加了abstract反而会报错 def delete(id:String):Boolean def add(o:Any):Boolean def update(o:Any):Int def query(id:String):List[Any] } |
2. 带具体实现的trait
|
trait DAO{ //delete方法有具体实现 def delete(id:String):Boolean={ println("delete implementation") true } def add(o:Any):Boolean def update(o:Any):Int def query2(id:String):List[Any] } |
从字节码文件可以看出,带有具体实现的trait是通过java中的抽象类来实现的。
|
|
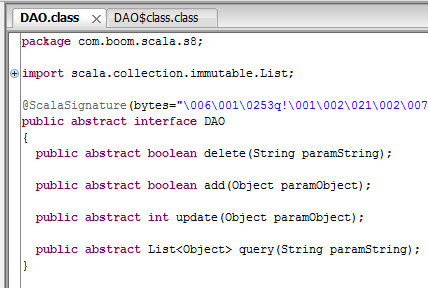
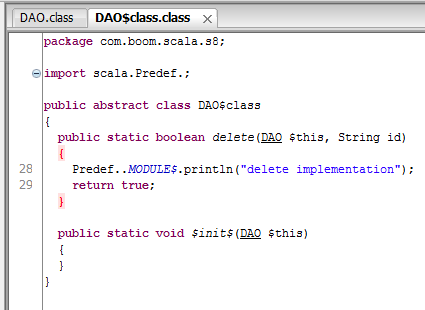
3. 带抽象字段的trait
|
trait DAO{ var recodeMount:Long def delete(id:String):Boolean={ println("delete implementation") true } def add(o:Any):Boolean def update(o:Any):Int def query(id:String):List[Any]
} |
|
通过函数的方式定义抽象类字段:
|

4. 具体字段的trait
|
trait DAO{ var recodeMount:Long=15000000000000L def delete(id:String):Boolean={ println("delete implementation") true } def add(o:Any):Boolean def update(o:Any):Int def query(id:String):List[Any] } |
|
|


(六)trait构造顺序
在前一讲当中我们提到,对于不存在具体实现及字段的trait,它最终生成的字节码文件反编译后是等同于Java中的接口,而对于存在具体实现及字段的trait,其字节码文件反编译后得到的java中的抽象类,它有着Scala语言自己的实现方式。因此,对于trait它也有自己的构造器,trait的构造器由字段的初始化和其它trait体中的语句构成,下面是其代码演示:
|
package com.boom.scala.s8 import java.io.PrintWriter trait Logger{ println("Logger") def log(msg:String):Unit } trait FileLogger extends Logger{ println("FilgeLogger") val fileOutput=new PrintWriter("file.log") fileOutput.println("#") def log(msg:String):Unit={ fileOutput.print(msg) fileOutput.flush() } } object TraitDemo{ def main(args: Array[String]): Unit = { //匿名类 new FileLogger{ }.log("trat demo") } } |
|
Logger FilgeLogger |
|
file.log: # trat demo |
通过上述不难发现,在创建匿名类对象时,先调用的是Logger类的构造器,然后调用的是FileLogger的构造器。实际上构造器是按以下顺序执行的:
1. 如果有超类,则先调用超类的构造器
2. 如果有父trait,它会按照继承层次先调用父trait的构造器
3. 如果有多个父trait,则按顺序从左到右执行
4. 所有父类构造器和父trait被构造完之后,才会构造本类
|
class Personclass Student extends Person with FileLogger with Cloneable |
上述构造器的执行顺序为:
1. 首先调用父类Person的构造器
2. 调用父trait Logger的构造器
3. 再调用trait FileLogger构造器
4. 再然后调用Cloneable的构造器
5. 最后才调用Student的构造器
(七)trait与类的比较
通过前一小节,可以看到,trait有自己的构造器,它是无参构造器,不能定义trait带参数的构造器,即:
|
//不能定义trait带参数的构造器 trait FileLogger(msg:String) |
除此之外 ,trait与普通的scala类并没有其它区别,在前一讲中我们提到,trait中可以有具体的、抽象的字段,也可以有具体的、抽象的方法,即使trait中没有抽象的方法也是合理的,如:
|
trait Logger{ println("Logger") def log(msg:String):Unit } //FileLogger里面没有抽象的方法 trait FileLogger extends Logger{ println("FilgeLogger") val fileOutput=new PrintWriter("file.log") fileOutput.println("#") def log(msg:String):Unit={ fileOutput.print(msg) fileOutput.flush() } } |
(八)提前定义与懒加载
前面的FileLogger中的文件名被写死为”file.log”,程序不具有通用性,这边对前面的FileLogger进行改造,把文件名写成参数形式,代码如下:
|
trait Logger{ def log(msg:String):Unit } trait FileLogger extends Logger{ //增加了抽象成员变量 val fileName:String //将抽象成员变量作为PrintWriter参数 val fileOutput=new PrintWriter(fileName:String) fileOutput.println("#") def log(msg:String):Unit={ fileOutput.print(msg) fileOutput.flush() } } |
这样的设计会存在一个问题,虽然子类可以对fileName抽象成员变量进行重写,编译也能通过,但实际执行时会出空指针异常,完全代码如下:
上述代码在编译时不会有问题,但实际执行时会抛异常,异常如下:
|
Exception in thread "main" java.lang.NullPointerException at java.io.FileOutputStream.<init>(Unknown Source) at java.io.FileOutputStream.<init>(Unknown Source) at java.io.PrintWriter.<init>(Unknown Source) at com.boom.scala.s8.FileLogger$class.$init$(Logger.scala:70) at com.boom.scala.s8.Student.<init>(Logger.scala:79) at com.boom.scala.s8.TraitDemo$.main(Logger.scala:85) at com.boom.scala.s8.TraitDemo.main(Logger.scala)
|
具体原因就是构造器的执行顺序问题
|
class Student extends Person with FileLogger{ //Student类对FileLogger中的抽象字段进行重写 val fileName="file.log" } //在对Student类进行new操作的时候,它首先会 //调用Person构造器,这没有问题,然后再调用 //Logger构造器,这也没问题,但它最后调用FileLogger //构造器的时候,它会执行下面两条语句 //增加了抽象成员变量 val fileName:String //将抽象成员变量作为PrintWriter参数 val fileOutput=new PrintWriter(fileName:String)
// 此时fileName没有被赋值,被初始化为null,在执行new PrintWriter(fileName:String)操作的时候便抛出空指针异常 |
有几种办法可以解决前面的问题:
1. 提前定义
提前定义是指在常规构造之前将变量初始化,完整代码如下:
|
trait Logger{ def log(msg:String):Unit } trait FileLogger extends Logger{ val fileName:String val fileOutput=new PrintWriter(fileName:String) fileOutput.println("#") def log(msg:String):Unit={ fileOutput.print(msg) fileOutput.flush() } } class Person class Student extends Person with FileLogger{ val fileName="file.log" } object TraitDemo{ def main(args: Array[String]): Unit = { val s=new { //提前定义 override val fileName="file.log" } with Student s.log("predifined variable ") } } |
显然,这种方式编写的代码很不优雅,也比较难理解。此时可以通过在第一讲中提到的lazy即懒加载的方式
2. lazy懒加载的方式
|
trait Logger{ def log(msg:String):Unit } trait FileLogger extends Logger{ val fileName:String //将方法定义为lazy方式 lazy val fileOutput=new PrintWriter(fileName:String) //下面这条语句不能出现,否则同样会报错 //因此,它是FileLogger构造器里面的方法 //在构造FileLogger的时候便会执行 //fileOutput.println("#") def log(msg:String):Unit={ fileOutput.print(msg) fileOutput.flush() } } class Person class Student extends Person with FileLogger{ val fileName="file.log" } object TraitDemo{ def main(args: Array[String]): Unit = { val s=new Student s.log("predifined variable ") } } |
lazy方式定义fileOutput只有当真正被使用时才被初始化,例子中,当调用 s.log(“predifined variable “)时,fileOutput才被初始化,此时fileName已经被赋值了。
(九)trait扩展类
在本节的第7小节部分,我们给出了trait与类之间的区别,我们现在明白,trait除了不具有带参数的构造函数之外,与普通类没有任何区别,这意味着trait也可以扩展其它类。
|
trait Logger{ def log(msg:String):Unit }//trait扩展类Exception trait ExceptionLogger extends Exception with Logger{ def log(msg:String):Unit={ println(getMessage()) } } |
如果此时定义了一个类混入了ExceptionLogger ,则Exception自动地成为这个类的超类,代码如下:
|
trait Logger{ def log(msg:String):Unit } trait ExceptionLogger extends Exception with Logger{ def log(msg:String):Unit={ println(getMessage()) } } //类UnprintedException扩展自ExceptionLogger //注意用的是extends //此时ExceptionLogger父类Exception自动成为 //UnprintedException的父类 class UnprintedException extends ExceptionLogger{ override def log(msg:String):Unit={ println("") } } |
当UnprintedException扩展的类或混入的特质具有相同的父类时,scala会自动地消除冲突,例如:
|
//IOException具有父类Exception //ExceptionLogger也具有父类Exception //scala会使UnprintedException只有一个父类Exception class UnprintedException extends IOException with ExceptionLogger{ override def log(msg:String):Unit={ println("") } } |
(十)self type
下面的代码演示了什么是self type即自身类型
|
class A{ //下面 self => 定义了this的别名,它是self type的一种特殊形式 //这里的self并不是关键字,可以是任何名称 self => val x=2 //可以用self.x作为this.x使用 def foo = self.x + this.x } |
下面给出了内部类中使用场景
|
class OuterClass { outer => //定义了一个外部类别名 val v1 = "here" class InnerClass { // 用outer表示外部类,相当于OuterClass.this println(outer.v1) } } |
而下面的代码则定义了自身类型self type,它不是前面别名的用途
|
trait X{ } class B{ //self:X => 要求B在实例化时或定义B的子类时 //必须混入指定的X类型,这个X类型也可以指定为当前类型 self:X=> } |
自身类型的存在相当于让当前类变得“抽象”了,它假设当前对象(this)也符合指定的类型,因为自身类型 this:X =>的存在,当前类构造实例时需要同时满足X类型,下面给出自身类型的使用代码:
|
trait X{ def foo() } class B{ self:X=> } //类C扩展B的时候必须混入trait X //否则的话会报错 class C extends B with X{ def foo()=println("self type demo") } object SelfTypeDemo extends App{ println(new C().foo) } |
|
self type demo () |
评论
发表评论
|
|
|