scala系列(三)Set、Map、Tuple、队列操作 有更新!
- 37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
- (一)mutable、immutable集合
- scala集合类的层次结构
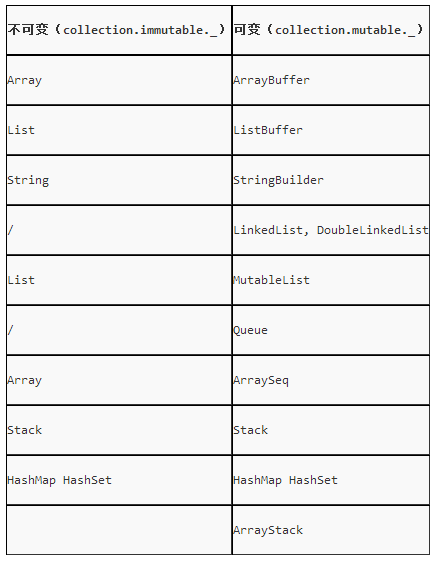
- 可变集合与不可变集合对应关系
- (二)Set操作
- (三)Map操作实战
- Option,None,Some类型
- (四)元组操作实战
- (五)队列操作
- (六)栈操作
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
(一)mutable、immutable集合
大致意思是:scala中的集合分为两种,一种是可变的集合,另一种是不可变的集合。可变的集合可以更新或修改,添加、删除、修改元素将作用于原集合。不可变集合一量被创建,便不能被改变,添加、删除、更新操作返回的是新的集合,老集合保持不变
scala中所有的集合都来自于scala.collection包及其子包mutable, immutable。
scala.collection.immutable包中的集合绝对是不可变的,函数式编程语言推崇使用immutable集合。包中的集合在是可变的,使用的时候必须明白集合何时发生变化。
scala.collection中的集合要么是mutalbe的,要么是immutable的。同时该包中也定义了immutable及mutable集合的接口。在scala中,默认使用的都是immutable集合,如果要使用mutable集合,需要在程序中引入
|
//由于immutable是默认导入的,因此要使用mutable中的集合的话 //使用如下语句 var ts2 = mutable.Set(1,2,3); println(ts2.getClass+"\t"+ts2); //不指定的话,创建的是immutable 集合 var mutableSet = Set(3,4,5,6); println(mutableSet.getClass+"\t"+mutableSet); |
|
class scala.collection.mutable.HashSet Set(1, 2, 3) class scala.collection.immutable.Set$Set4 Set(3, 4, 5, 6) |
直接使用Set(1,2,3)创建的是immutable集合,这是因为当你不引入任何包的时候,scala会默认导入以几个包: 
Predef对象中包含了Set、Map等的定义 
scala集合类的层次结构
scala.collection包中的集合类层次结构如下图: 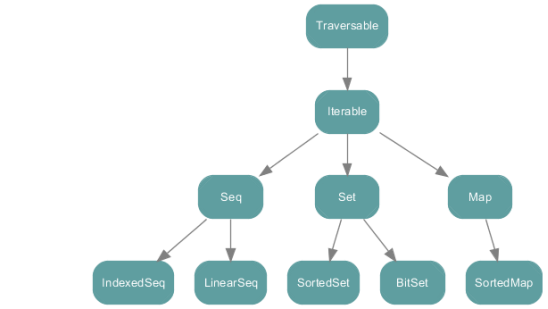
包中的类层次结构: 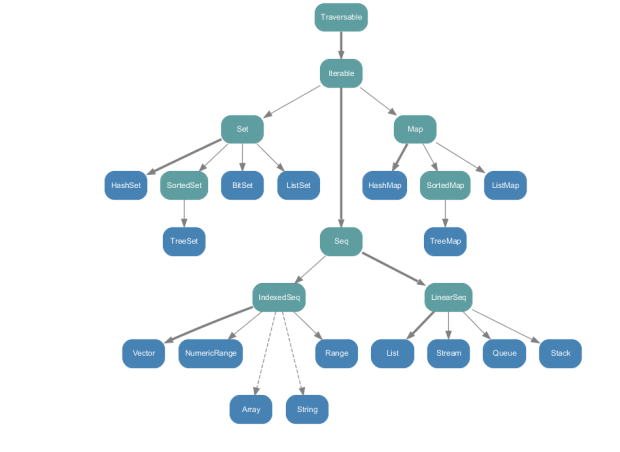
scala.collection.mutable包中的类层次结构:
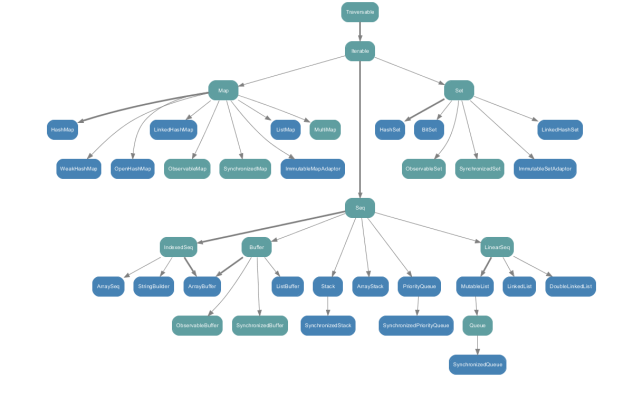
可变集合与不可变集合对应关系
(二)Set操作
Set(集)是一种不存在重复元素的集合,它与数学上定义的集合是对应的
|
//定义一个集合 //这里使用的是mutable val numsSet=mutable.Set(3.0,5) println(numsSet.getClass+"\t"+numsSet) //向集中添加一个元素,同前一讲中的列表和数组不一样的是 //,Set在插入元素时并不保元素的顺序 //默认情况下,Set的实现方式是HashSet实现方式, //集合中的元素通过HashCode值进行组织 numsSet.add(6); numsSet.+=(7,9,12); println(numsSet) |
|
class scala.collection.mutable.HashSet Set(5.0, 3.0) Set(5.0, 3.0, 7.0) |
|
// 如果对插入的顺序有着严格的要求,则采用scala.collection.mutalbe.LinkedHashSet来实现 val linkedHashSet=scala.collection.mutable.LinkedHashSet(3.0,5) linkedHashSet.+=(6,2,34) println(linkedHashSet); |
|
Set(3.0, 5.0, 6.0, 2.0, 34.0) |
(三)Map操作实战
Map是一种键值对的集合,一般将其翻译为映射
|
// 直接初始化 // ->操作符,左边是key,右边是value // 默认不可变 val studentInfo=Map("john" -> 21, "stephen" -> 22,"lucy" -> 20) println(studentInfo) // 定义一个空的Map val emptyMap = new scala.collection.mutable.HashMap[String,Int](); // 两种初始化方式 val xMap=scala.collection.mutable.Map(("spark",1),("hive",1)) val studentInfoMutable=scala.collection.mutable.Map("john" -> 21, "stephen" -> 22,"lucy" -> 20) studentInfoMutable.+=("mulin" -> 343) studentInfoMutable.put("ziyou", 100) // 遍历操作1 for(ele<-studentInfoMutable)print(ele._1+":"+ele._2+"\t"); // 遍历操作2 println() studentInfoMutable.foreach(e=>{print(e._1+":"+e._2+"\t")}) // 遍历操作3 println() studentInfoMutable.foreach(e=>{val (k,v) = e; print(k+":"+v+"\t")}) println() println(studentInfoMutable.contains("ziyou")) println(studentInfoMutable.get("ziyou")) println(studentInfoMutable.get("ziyouxx")) |
|
Map(john -> 21, stephen -> 22, lucy -> 20) ziyou:100 mulin:343 john:21 lucy:20 stephen:22 ziyou:100 mulin:343 john:21 lucy:20 stephen:22 ziyou:100 mulin:343 john:21 lucy:20 stephen:22 true Some(100) None |
Option,None,Some类型
Option、None、Some是scala中定义的类型,它们在scala语言中十分常用,因此这三个类型非学重要。
None、Some是Option的子类,它主要解决值为null的问题,在Java语言中,对于定义好的HashMap,如果get方法中传入的键不存在,方法会返回null,在编写代码的时候对于null的这种情况通常需要特殊处理,然而在实际中经常会忘记,因此它很容易引起 NullPointerException异常。在Scala语言中通过Option、None、Some这三个类来避免这样的问题,这样做有几个好处,首先是代码可读性更强,当看到Option时,我们自然而然就知道它的值是可选的,然后变量是Option,比如Option[String]的时候,直接使用String的话,编译直接通不过。
|
// 获取实际值 println(show(studentInfoMutable.get("ziyou"))) println(show(studentInfoMutable.get("ziyouxx"))) println(studentInfoMutable.get("ziyou").get) println(studentInfoMutable.get("ziyoudd").get) def show(x:Option[Int]) = x match { case Some(a) => a case None => 0 } |
|
100 0 100 Exception in thread "main" java.util.NoSuchElementException: None.get at scala.None$.get(Option.scala:313) at scala.None$.get(Option.scala:311) at com.boom.scala.s3.ImmutableDemo$.main(ImmutableDemo.scala:43) at com.boom.scala.s3.ImmutableDemo.main(ImmutableDemo.scala) |
(四)元组操作实战
前面我们提到Map是键值对的集合,元组则是不同类型值的聚集。
|
var tuple = ("hello","china",1); println(tuple._1) //通过模式匹配获取元组内容 val (h,c,a) = tuple; println(a) |
|
hello 1 |
模式匹配
val (h,c,a) = tuple;
val (k,v) = e;
(五)队列操作
|
var queue=scala.collection.immutable.Queue(10,20,30) println(queue); |
(六)栈操作
TODO
评论
发表评论
|
|
|