flume系列(一) 有更新!
37套精品Java架构师高并发高性能高可用分布式集群电商缓存性能调优设计项目实战视教程 置顶! 有更新!
一、理论基础
(一)Flume简介
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据的简单处理,并将数据处理结果写入各种数据接收方的能力。
Flume作为Cloudera开发的实时日志收集系统,受到了业界的认可与广泛应用。2010年11月Cloudera开源了Flume的第一个可用版本0.9.2,这个系列版本被统称为Flume-OG。随着Flume功能的扩展,Flume-OG代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在Flume-OG的最后一个发行版本 0.94.0中,日志传输不稳定的现象尤为严重。为了解决这些问题,2011年10月Cloudera重构了核心组件、核心配置和代码架构,重构后的版本统称为Flume-NG。改动的另一原因是将 Flume 纳入 Apache 旗下,Cloudera Flume改名为Apache Flume。
(二)Flume工作原理
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。以下是Flume的一些核心概念:
(1)Events:一个数据单元,带有一个可选的消息头,可以是日志记录、avro 对象等。
(2)Agent:JVM中一个独立的Flume进程,包含组件Source、Channel、Sink。
(3)Client:运行于一个独立线程,用于生产数据并将其发送给Agent。
(4)Source:用来消费传递到该组件的Event,从Client收集数据,传递给Channel。
(5)Channel:中转Event的一个临时存储,保存Source组件传递过来的Event,其实就是连接 Source 和 Sink ,有点像一个消息队列。
(6)Sink:从Channel收集数据,运行在一个独立线程。
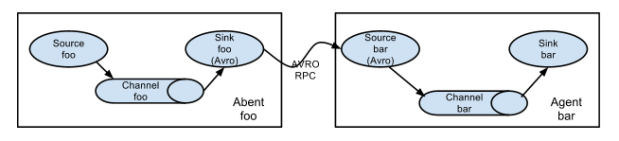
Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM。单Agent由Source、Sink和Channel三大组件构成,如下图所示:

值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source、Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上;Sink可以把日志写入HDFS、Hbase、ES甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说多个Agent可以协同工作,如下图所示:
评论
发表评论
|
|
|